Основы Нейросетевых технологий.
Начну с того, что все это только для того, чтобы
Вы поняли основные принципы работы нейросетей. Прежде всегео разберемся для
чего они и как вообще их придумали. На самом деле ни кто, ни чего не
придумывал, а просто сделали математическую модель реального нейрона (нейрон
или нейроцит - это нервная клетка, из которых состоит наша нервная система, в
том числе и мозг). Перед тем как рассмотрим модель нейрона, я хочу показать вам
тот самый нейрон, только “живой”.
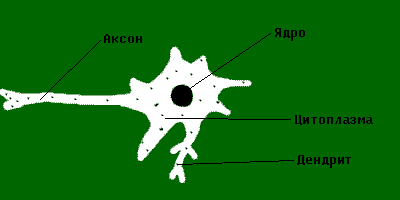
Как Вы думаете, для чего нужен аксон? Правильно,
для соединения с этого нейрона с другими, их может быть от одного до нескольких
миллионов и это (аксон) одно из самых важных образований для нас. Дендриты же
гораздо короче аксонов (где-то в 1000-5000 раз) и они нам как программистам не
нужны, поэтому не будем останавливаться на них. Ядро и цитоплазма для нас тоже
не играют никакой роли.
Сейчас хочу представить вам
простейшую нейросеть, состоящую из Зх входных нейронов, 2х нейронов в скрытом
слое и одного выходного.
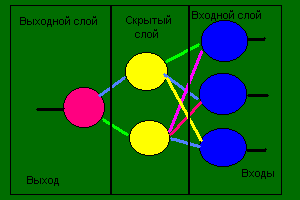
Эта нейросеть является Зх слойной. Посмотрите на
какой-нибудь входной нейрон, Вы видите, что у него 2 аксона. У скрытых - по
одному и у выходного - только один и тот является выходом. Ну ладно хватит
анатомии, приступим к математике...
Так, теперь договоримся аксоны называть связями,
сигналы нервных клеток - активностью, а нейроны - нейронами. Сейчас я попытаюсь
дать описание модели “Идеального нейрона”: Все что поступает на вход нейрона,
умножается на вес и суммируется, потом получившаяся величина обрабатывается
сигмоидальной (или пороговой или линейной или вообще никакой) функцией.
Выглядит это примерно вот так:
Y=Function(X1*W1+X2*W2+X3*W3+... +Xn*Wn)
где Y - выход нейрона, Function() - сигмоидальная
или пороговая или линейная или вообще никакая функция, X1,X2,X3...Xn - входная
активность (или выходная активность нейронов предыдущего слоя), W1,W2,W3...Wn -
веса соответствующие каждый своей связи, X*W - называется взвешенным входом.
Чтобы начать рассказ об обучении сети расскажу о
том, как она работает:) А работает она очень просто - вот, например сеть,
которая будет распознавать два образа (ноль и единицу), отличать один от
другого. Сделаем, например, на входе матрицу 20х20, то есть 400 входов, назовем
её для дальнейших манипуляций двумерным массивом Input[0..19,0..19] в котором
все величины могут быть равными либо 0 либо 1. Скрытого слоя делать не будем, а
сделаем сразу два выхода (так как два ответа), примем первый выход Out [0] за
ответ “0”, Out [1] за ответ “1” и на каком из выходов активность будет больше
тот ответ и верен.
Приведу
пример этой программы на Паскале только без функции обучения.
var
Input : Array[0..19,0..19] of Byte;
Out : Array[0..1] of Extended;
W : Array[0..19,0..19,0..1] of
Extended;
i, j, k : Byte;
begin
for i:=0 to 19 do
for j:=0 to 19 do
for k:=0 to 1 do
Out[k]:=Out[k]+Input[i, j]*W[i, j, k];
WriteLn('Выходная активность ответа "0" равна '+ FloatToStr(Out[0]));
WriteLn('Выходная активность ответа "1" равна '+ FloatToStr(Out[1]));
if Out[0]>0ut[1] then WriteLn('Образ является нулём') else WriteLn(''Образ
является единицей');
end.
Как Вы успели заметить, суть обучения заключается в изменении весов. Самый распространенный алгоритм обучения это “Алгоритм Обратного Распространения”.
ОБУЧЕНИЕ
Ну, вот я начал продолжение статьи, теперь
обсудим обучение этой сети. Прежде, в общих чертах опишу сей алгоритм. Он
заключается в вычислении квадрата ошибки определенной связи от требуемого
выходного значения и вычитании определяемой величины из веса связи. Можете не
вникать в выше написанное, сейчас я все разъясню на нашем примере, только
добавим ещё к нашей сети скрытый (промежуточный) слой нейронов, для того чтобы
показать, как обучаются нейроны скрытого слоя (там все немного по-другому).
Programm NeuroNet;
var
Input : Array[0..19,0..19] of Byte; //Входы
HL : Array[0..149] of Extended; //Скрытый слой
Out : Array[0..1] of Extended; //Выходы
W1 : Array[0..19,0..19,0..149] of Extended; //Веса между элементами входного и
скрытого слоёв
W2 : Array[0..149,0..1] of Extended; //Веса между элементами скрытого и
выходного слоёв
B1 : Array[0..19,0..19] of Extended; //Производные ошибок
B2 : Array[0..149] of Extended; //Производные ошибок
B3 : Array[0..1] of Extended; //Производные ошибок
D : Array[0..1] of Extended; //Желаемые выходы
SIG : Real; //Скорость обучения
i, j, k : Byte;
begin
function Sigmoid(X : Extended):Extended;
var
Res :Extended;
begin
Res:=1/(1+exp(-X));
Sigmoid:=Res;
end;
Procedure CalculateAnswer;
begin
for i:=0 to 19 do
for j:=0 to 19 do
for k:=0 to 149 do
HL[k]:=HL[k]+Input[i, j]*W1[i, j, k];
for k:=0 to 149 do HL[k]:=Sigmoid(HL[k]);
for i:=0 to 149 do
for j:=0 to 1 do
Out[j]:=Out[j]+HL[i]*W2[i, j];
for k:=0 to 149 do HL[k]:=Sigmoid(HL[k]);
end;
Procedure ShowAnswer;
begin
WriteLn('Выходная активность ответа "0" равна '+ FloatToStr(Out[0]));
WriteLn('Выходная активность ответа "1" равна '+ FloatToStr(Out[1]));
if Out[0]>0ut[1] then WriteLn('Образ является нулём') else WriteLn(''Образ
является единицей');
end;
end.
Вот так теперь выглядит наша программа,
как вы успели заметить, для удобства я её полностью структурировал. Так что
теперь буду просто писать процедуры, которые надо будет просто добавлять в
программу. УЧТИТЕ: Я ЭТУ ПРОГУ НЕ ТЕСТИЛ, так что если что не работает, то
думайте сами или пишите мне. Теперь я напишу принцип обучения.
- Выбор скорости обучения
SIG (0<SIG<1),
- Пока сеть не обучится,
- Для каждого образца входных сигналов,
- Получить значения для
каждого элемента сети (CalculateAnswer),
- Для всех выходных
элементов вычислить B[j](GetErrors),
- Для всех остальных
элементов (от последнего к первому) вычислить B[j](GetErrors),
- Все веса
изменить на dW (CorrecrW).
- Вот вродебы всё, теперь
приступим к описанию этих процедур и рассмотрению их алгоритма. Начнем с
GetErrors.
Procedure GetErrors;
begin
for i:=0 to 1 do B3[i]:=Out[i]-D[i];
for i:=0 to 149 do
for j:=0 to 1 do
B2[i]:=B2[i]+W2[i,j]*Out[j]*(1-Out[j]);
{
for i:=0 to 19 do
for j:=0 to 19 do
for k:=0 to149 do
B1[i,j]:=B1[i,j]+W1[i,j]*HL[k]*(1-HL[k])*B2[k];
}
end;
Как Вы поняли мы сделали проход по сети задом
наперед и получили производные от ошибок для каждого элемента. Если Вы все
поняли, то приступим к рассмотрению процедуры CorrectW.
Procedure CorrectW;
begin
for i:=0 to 19 do
for j:=0 to 19 do
for k:=0 to149 do
W1[i,j,k]:=W1[i,j,k]-SIG*Input[i,j]*HL[k]*(1-HL[k])*B2[k];
for i:=0 to 149 do
for j:=0 to 1 do
W2[i,j]:=W2[i,j]-SIG*HL[i]*Out[j]*(1-Out[j])*B3[j];
end;
Вот в принципе и все про обучение нейросетей с
учителем. Надеюсь своим последним словом я вас заставил спросить меня: “А что,
ещё и без учителя можно?" Да можно и об этом я напишу позже, а пока скажу,
что когда Вы в гордом одиночестве о чем-то рассуждаете ваш мозг, а точнее его
нейроны продолжают учиться, учиться и ещё раз учиться как завещал великий(и
ушастый) Ленин как учит коммунистическая партия!!!(Во сказал-то:)
P.S.: Заранее прошу прощения за грамматические
ошибки и особенно прошу прощения у математиков, все неточности были допущены,
потому что я не имею специального образования в области высшей математики, а
являюсь всего лишь медиком. Следите за обновлением.